Introduction
Welcome to this kafka tutorial. Apache Kafka is a distributed streaming platform used to build real-time data pipelines and streaming applications. In this tutorial you’ll learn what Kafka is, how it works, when to use it, and get hands-on examples to help you get started quickly.
What is Apache Kafka?
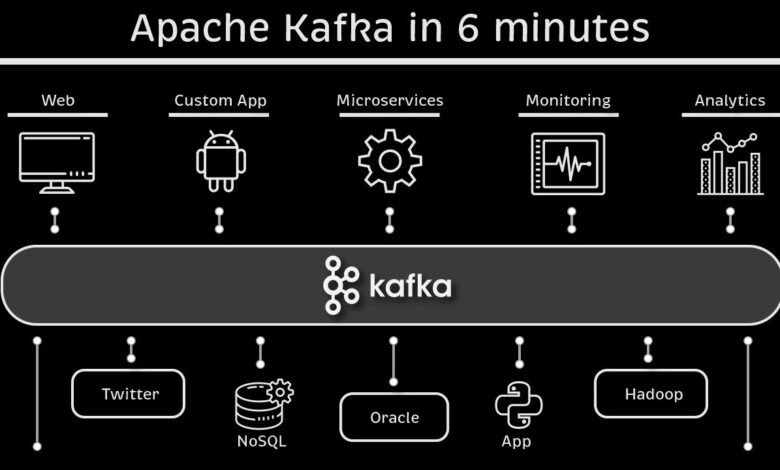
Apache Kafka is a high-throughput, low-latency platform for handling real-time data feeds. It was originally developed at LinkedIn and later open-sourced. Kafka is often described as a distributed commit log — it persistently stores messages in the order they arrive and lets many producers and consumers read and write those messages concurrently.
Core Concepts (quick overview)
- Topic: A named stream of records. Think of a topic as a category or feed name (for example,
ordersorclicks). - Partition: Each topic is split into partitions. Partitions provide parallelism and ordered logs. Every message within a partition has an offset (a sequential id).
- Broker: A Kafka server that stores data and serves clients. A Kafka cluster is a group of brokers.
- Producer: An application that writes (publishes) messages to Kafka topics.
- Consumer: An application that reads messages from Kafka topics.
- Consumer Group: A group of consumers that coordinate to read from a topic’s partitions so each message is processed by only one consumer in the group.
- Retention: How long Kafka keeps messages. Kafka can keep messages for hours, days, or indefinitely depending on configuration.
Kafka architecture — simple explanation
Kafka stores messages in topics split into partitions. Each partition is an ordered, append-only sequence of messages. Brokers host partitions; leaders for partitions handle reads and writes while followers replicate those messages. This replication gives fault tolerance.
Producers push messages to topics. Consumers pull messages from topics and track offsets (where they left off). Consumer groups allow scaling consumers horizontally while ensuring each message is processed once by the group.
When to use Kafka
Kafka is a great fit when you need:
- High-volume messaging with low latency (millions of messages per second).
- Durable storage of event streams for replay.
- Real-time processing (stream processing) with frameworks like Kafka Streams, Flink, or Spark.
- Decoupling of microservices through an event-driven architecture.
Avoid Kafka for small, simple queueing where heavyweight durability and scale aren’t needed a lighter queue may be easier to run.
Quick setup (local, minimal)
This is a short orientation to try Kafka locally. For production, follow the official docs for secure, replicated clusters.
Option A — Using Docker Compose (fast)
Create a docker-compose.yml with Kafka and a ZooKeeper or KRaft configuration. Many examples exist; Docker allows you to run a broker quickly and start producing and consuming messages.
Option B — Download binary (manual)
- Download Kafka binary from the Apache website.
- Extract and run the broker (and ZooKeeper if your Kafka version requires it).
- Use bundled command-line tools to create topics, produce, and consume messages.
Basic commands (CLI examples)
These commands are conceptual details depend on your Kafka build and environment.
- Create a topic:
$ kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
- Produce messages (console producer):
$ kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092
> Hello Kafka
> Another message
- Consume messages (console consumer):
$ kafka-console-consumer.sh --topic my-topic --bootstrap-server localhost:9092 --from-beginning
Simple producer & consumer examples
Java (high-level sketch)
// using org.apache.kafka:kafka-clients
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my-topic", "key1", "Hello from Java"));
producer.close();
Python (using confluent-kafka or kafka-python)
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my-topic', b'hello kafka from python')
producer.flush()
Consumer groups and scaling
When multiple consumers belong to the same consumer group, Kafka assigns partitions to consumers so each partition is read by exactly one consumer in the group. If you need more throughput, increase partitions then add consumers (in the same group) to parallelize processing.
Ordering guarantees
Kafka guarantees the order of messages within a partition. If global ordering is required across all messages you must design carefully (e.g., use a single partition or implement ordering logic in your consumers), but single partition limits throughput.
Durability and retention details
Kafka writes data to disk and can replicate partitions across brokers. You configure retention based on time (e.g., 7 days) or size (e.g., 100GB). You can also enable compaction for topics where you want to keep only the latest value per key.
Monitoring & operations (brief)
- Monitor broker health, partition distribution, consumer lag, and throughput.
- Tools: JMX metrics, Cruise Control, Confluent Control Center, Prometheus + Grafana.
- Plan for broker failures by setting an appropriate replication factor (commonly 3 in production) and ensuring proper partition leadership balance.
Security essentials
For production, enable:
- Encryption (TLS) for data-in-transit.
- Authentication (SASL) for clients.
- Authorization (ACLs) to control who can read/write topics.
Stream processing with Kafka
Kafka has a stream processing library, Kafka Streams, which allows you to build stateful streaming applications directly against Kafka topics. Alternatives include using Flink, Spark Structured Streaming, or ksqlDB for SQL-like stream processing.
Common pitfalls & best practices
- Too few partitions: Limits consumer parallelism and throughput.
- Too many small partitions: Increases overhead and memory usage on brokers.
- Ignoring replication: Run with
replication-factor >= 2(preferably 3) to survive broker failures. - Not monitoring consumer lag: Lag means consumers are falling behind producers.
- Using long retention without need: Storage costs can grow; manage retention policies.
Resources to learn more
Search for official Apache Kafka documentation, the Kafka Improvement Proposals (KIPs) for advanced topics, and tutorials from trusted blogs and vendor docs (Confluent, etc.) when you want deeper, version-specific guidance.
Conclusion
This kafka tutorial covered the essential concepts, a quick local setup, basic producer/consumer examples, and operational tips. Kafka is a powerful tool when you need reliable, high-throughput streaming and event-driven systems. Start simple, run locally or with Docker, and iterate toward production-ready configuration.



